Arm, принадлежащий SoftBank, продолжает доминировать на рынке архитектуры с низким энергопотреблением и эффективными процессорами, которые используются сегодня на подавляющем большинстве смартфонов на рынке. Хотя Arm не производит никаких собственных продуктов, оставляя это на усмотрение широкого круга партнеров, линейка Cortex вездесуща в кремниевых разработках всех ведущих игроков.
В прошлом году Arm повысила производительность, выпустив , предлагая на 35% больше производительности по сравнению с предыдущим поколением, а также специальные улучшения для машинного обучения. Таким образом, Cortex-A76 многое сделал для повышения производительности однопоточности по сравнению со своим предшественником.

На этом фоне Arm уже год выпускает новый улучшенный процессор Cortex-A77. Якобы такие же, как и у его предшественника, с точки зрения высокого уровня, инженеры Arm внесли изменения в конструкцию, чтобы значительно увеличить количество инструкций за такт.
Таким образом, цель состояла в том, чтобы повысить производительность посредством улучшений IPC, не увеличивая ключевой ограничитель: мощность. Так как же Arm смог претендовать на красивые однопоточные улучшения без масштабного пересмотра дизайна? Читать дальше.

Эта блок-схема подчеркивает сходства и архитектурные улучшения по сравнению с Cortex-A76. Давайте возьмем каждого по очереди.
Трата времени и ресурсов на этот интерфейсный блок улучшает способность процессора оптимизировать поток команд, поступающих в области выборки, декодирования и отправки, что позволяет процессору, так сказать, кормить исполняющего зверя.
Отличное место для начала — модуль прогнозирования ветвлений (BPU), который, как следует из названия, пытается угадать, куда пойдет ветвь. Причина ветвления заключается в том, чтобы поддерживать процессор как можно более загруженным, выполняя инструкции не последовательным образом — внеочередную обработку — поэтому архитекторы обычно тратят здесь много времени и усилий. Компромисс между усилением BPU заключается в увеличении мощности и площади кремния, поэтому это прекрасный баланс для архитектуры с ограничением TDP, такой как Cortex-A77.
Прогнозирование веток и использование СС
Тем не менее, поскольку этот новый Cortex имеет более мощное ядро выполнения — подробнее об этом — BPU также нуждается в обновлении. Таким образом, Arm удваивает пропускную способность предсказания ветвления, до 64 байтов за цикл, и, следовательно, сглаживает любые нежелательные пузырьки — там, где ничего не происходит в течение этого цикла — от основного ядра. Есть также какой-то секретный соус, который уменьшает вероятность ошибочных прогнозов. Помните, что неправильно на первом этапе нужно очистить весь конвейер, что является дорогостоящим с точки зрения энергопотребления и производительности. В совокупности Cortex-A77 имеет больший целевой буфер ветвления (имеет неявный смысл) и намного больший вход L1-BTB.
Интересной частью внешнего интерфейса является наличие микрооперационного кэша (обозначенного как MOP), также присутствующего на последних процессорах x86 от Intel и AMD. Цель MOP проста: хранить / кэшировать инструкции по мере их декодирования. Преимущество этого кэша состоит в том, что он позволяет выборочной части проекта, показанной выше, извлекать инструкцию из кэша и экономить электроэнергию, не требуя выяснения необходимых инструкций с нуля. Это также сокращает шаг от конвейера до 10 циклов, так что это беспроигрышный вариант во всем раунде.
Конечно, указывая на очевидное, микрооперационный кеш работает по инструкциям «второй раз» (потому что это хранимый кеш), что означает, что выигрыш в производительности не будет очевиден при первом запуске инструкций. Будучи включенным в i-кэш L1, Arm считает, что размер MOP 1,5 КБ (около 6 КБ для обычного кеша инструкций) имеет скорость попадания около 85% в широком диапазоне рабочих нагрузок. Кэш MOP имеет огромное значение для сред с ограниченным энергопотреблением, которые обычно разрабатывает Arm.
Один вопрос, который вы, возможно, задаете себе, заключается в том, почему Arm не внедрил выделенный кэш MOP в более ранних архитектурах, если он эффективен для повышения производительности при одновременном потенциальном снижении энергопотребления? Ответ двоякий: это не тривиальная задача, и, во-вторых, производительность процессора должна быть достаточно сильной, чтобы гарантировать такой кэш. Cortex-A77 — первое, что Arm считает достаточно хорошим, чтобы извлечь выгоду из увеличения общего силиконового следа.
Широкий и умный
Переходя к декодированию, поклонники архитектуры поймут, что Arm увеличивает пропускную способность диспетчеризации на 50 процентов, с четырех команд за цикл до шести. Эта ширина сохраняется до регистрации переименования / отправки, и общая диспетчеризация на ядре выполнения увеличивается с восьми на Cortex-A76 до 10 здесь. Чтобы вместить такие изменения, нужно большее окно не по порядку, чтобы оно перепрыгнуло со 128 записей до 160, снова питая исполняющего зверя.
Эта ширина передней и средней части не годится, если вы не можете ее использовать. Cortex-A77 приносит с собой второй бренд и третий арифметико-логический блок (ALU) для более параллельной обработки команд. На верхнем уровне исполнительного ядра рассматривается увеличение обработки на 50% — Cortex-A76 имеет одну ветвь, двойное ALU и многоцелевое ALU, поэтому здесь отсутствуют две дополнительные возможности исполнения, доступные здесь. Хотя это и не показано явно, у Cortex-A77 есть и второй канал AES. Также стоит отметить, что Cortex-A77 использует единую очередь команд из-за повышенной эффективности.
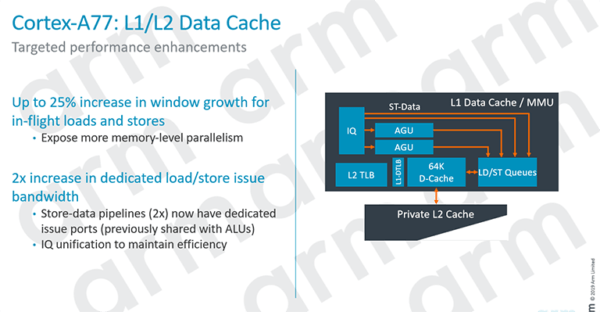
Другим интересным отличием является то, как функционирует блок управления памятью, и это область, в которой Arm добивается значительного прироста производительности. Прежде всего, по сравнению со своим предшественником, Cortex-A77 обеспечивает конвейерам с датой хранения прямой доступ к очереди проблем — он представлен на блок-схеме двумя самыми верхними оранжевыми линиями в MMU. На самом деле это означает дополнительную пропускную способность, что всегда хорошо.
Очередь load-store, как следует из названия, отвечает за загрузку и хранение данных в и из памяти, поэтому с точки зрения дизайна все, что можно сделать для повышения эффективности этого процесса, приносит немалые дивиденды. Arm использует так называемый «предварительный сборщик данных следующего поколения», который предлагает множество преимуществ, в том числе обеспечивает более широкую полосу пропускания из основной памяти, снижает необходимость заходить так далеко и в результате повышает энергоэффективность.
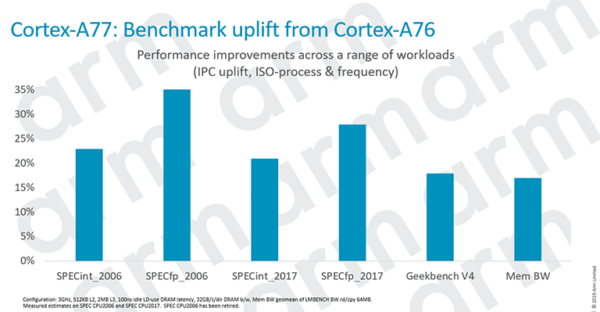
Сумма всех этих архитектурных изменений — более интеллектуальный интерфейс, более широкая диспетчеризация и выполнение, а также более интеллектуальная предварительная выборка данных — в целом улучшается на 20% по сравнению с Cortex-A76 на ровном игровом поле.
Можно ожидать приличного прироста в целочисленном тестировании, но немного удивляет прирост производительности с плавающей запятой, в основном за счет более умного обращения с памятью. Конечно, нельзя считать эталонные тесты SPEC евангелием — некоторые части тестов работают очень хорошо на Cortex-A77, возможно, слишком хорошо, но вывод состоит в том, что любой смартфон, оснащенный этим процессором, должен предлагать легкий переход для дизайнера SoC и дополнительный скачок производительности во всех сценариях.
Производитель смартфонов должен решить, сколько ядер сложить, на какой скорости и т. Д., Хотя сравнение с яблоками и яблоками означает, что аппаратное обеспечение Cortex в следующем году должно оставаться конкурентоспособным.
ARM сделала очень здоровые шаги в производительности при переходе от Cortex-A75 к Cortex-A76. Новейшая итерация строится на основе Cortex-A76 и повышает производительность, делая ее более широкой конструкцией … и все это без значительного увеличения мощности или занимаемой площади. Две выдающиеся функции — кэш MOP и совершенно новый предварительный выбор — делают все возможное, чтобы повысить все важные IPC.
ARM вышла на новый уровень с новым процессорным ядром Cortex-A77, которое неизбежно заменит нынешний Cortex-A76 в качестве выбора для ряда премиальных разработчиков SoC. Лучше, чем его предшественник во всех отношениях, и достаточно хорошие, или, так сказать, эталонные тесты, чтобы быть настоящим процессором класса ноутбука, мы ждем затаив дыхание, чтобы увидеть, сможет ли Arm наконец сломать хватку x86 в этом пространстве.




 и просто люмены (Lumens) в проекторах и медиа технике")



{kind=link}